Revista Biomédica Revisada Por Pares

En la sección Series, Medwave publica artículos relacionados con el desarrollo y discusión de herramientas metodológicas para la investigación clínica, la gestión en salud, la gesión de la calidad y otros temas de interés. En esta edición se presentan dos artículos que forman parte del programa de formación en Medicina Basada en Evidencias que se dicta por e-Campus de Medwave. El artículo siguiente pertenece a la Serie "Estadística Aplicada a la Investigación en Salud".
Se dice que muchos fenómenos en el campo de la salud se distribuyen normalmente. Esto significa que si uno toma al azar un número suficientemente grande de casos y construye un polígono de frecuencias con alguna variable continua, por ejemplo peso, talla, presión arterial o temperatura, se obtendrá una curva de características particulares, llamada distribución normal. Es la base del análisis estadístico, ya que en ella se sustenta casi toda la inferencia estadística.
La gráfica de la distribución normal tiene la forma de una campana, por este motivo también es conocida como la campana de Gauss. Sus características son las siguientes:
• Es una distribución simétrica.
• Es asintótica, es decir sus extremos nunca tocan el eje horizontal, cuyos valores tienden a infinito.
• En el centro de la curva se encuentran la media, la mediana y la moda.
• El área total bajo la curva representa el 100% de los casos.
• Los elementos centrales del modelo son la media y la varianza.
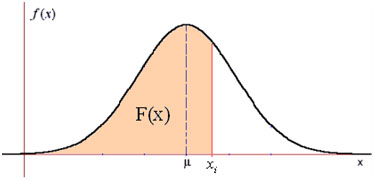
Esta distribución es un modelo matemático que permite determinar probabilidades de ocurrencia para distintos valores de la variable. Así, para determinar la probabilidad de encontrar un valor de la variable que sea igual o inferior a un cierto valor xi, conociendo el promedio y la varianza de un conjunto de datos, se debe reemplazar estos valores (media, varianza y xi) en la fórmula matemática del modelo. El cálculo resulta bastante complejo pero, afortunadamente, existen tablas estandarizadas que permiten eludir este procedimiento.
En el gráfico, el área sombreada corresponde a la probabilidad de encontrar un valor de la variable que sea igual o inferior a un valor dado. Esa probabilidad es la que aprenderemos a determinar usando una tabla estandarizada.
La tabla de la distribución normal presenta los valores de probabilidad para una variable estándar Z, con media igual a 0 y varianza igual a 1.
Para usar la tabla, siempre debemos estandarizar la variable por medio de la expresión:
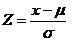
Siendo el valor de interés; la media de nuestra variable y su desviación estándar. Recordemos que y corresponden a parámetros, o sea valores en el universo, que generalmente no conocemos, por lo que debemos calcular Z usando los datos de nuestra muestra.
En general, el valor de Z se interpreta como el número de desviaciones estándar que están comprendidas entre el promedio y un cierto valor de variable x. En otras palabras, se puede decir que es la diferencia entre un valor de la variable y el promedio, expresada esta diferencia en cantidad de desviaciones estándar.
Suena abstracto, pero con un ejemplo se podrá entender mejor:
Supongamos un conjunto de personas con edad promedio 25 años y desviación estándar 3,86. Nuestro valor de interés (x) es 30 años. El valor de Z correspondiente será:
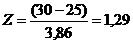
Este valor de Z nos dice que la edad de 30 años está a 1,29 desviaciones estándar sobre el promedio.
Ahora bien, la tabla de la distribución normal, entrega valores de probabilidad para los distintos valores de Z.
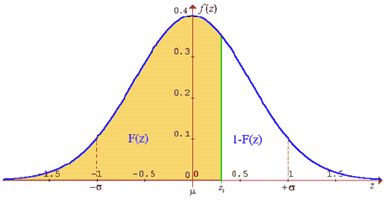
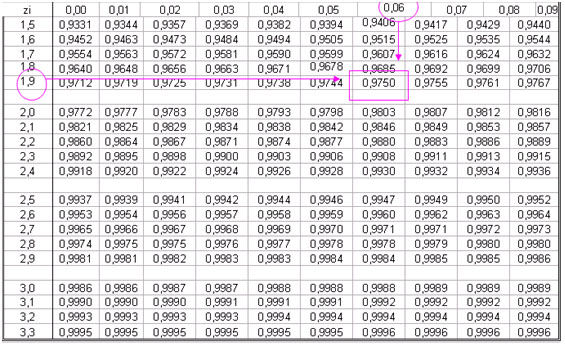
Lo averiguaremos con un valor concreto: ¿cuál es la probabilidad de encontrar un valor de Z menor o igual a 1,96?
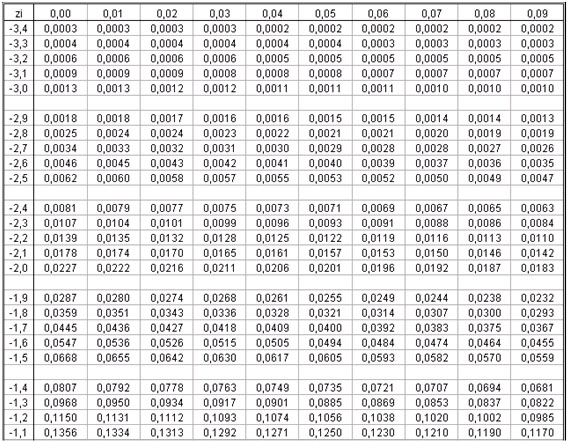
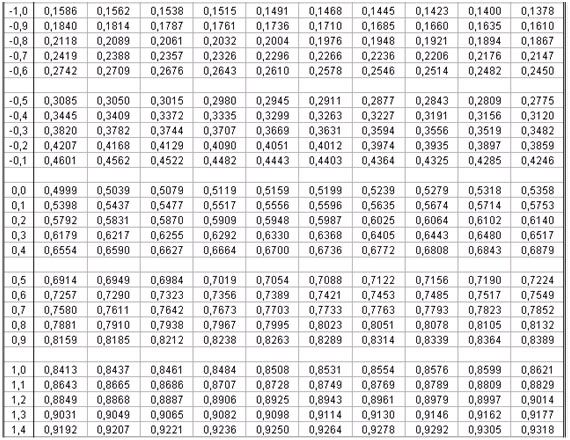
Vamos a la tabla y familiaricémonos con algunas de sus características.
▪ En la primera columna de la tabla aparece el entero y primer decimal del valor de Z, vemos que los valores van desde -3,4 a 3,3. En la primera fila (arriba), aparece el segundo decimal del valor de Z y, como es lógico, hay 10 números (0,00 a 0,09).
▪ Entonces, para nuestro valor de Z = 1,96 buscaremos 1,9 en la primera columna de la tabla y 0,06 en la primera fila de la tabla. Trazaremos líneas perpendiculares desde esos valores y llegaremos a un número en el cuerpo de la tabla (véase la tabla más abajo, que tiene marcadas las dos perpendiculares de las que hablamos. El número que encontramos y que está destacado es: 0,9750.
▪ Por lo tanto, la probabilidad asociada a Z=1,96 es 0,9750, es decir, la probabilidad de encontrar un valor de Z menor o igual a 1,96 es 0,9750.
En nuestro ejemplo anterior, con la edad 30 años, vemos que el valor Z = 1,29 tiene una probabilidad asociada de 0,9014. Entonces, la probabilidad de encontrar una persona con edad de 30 años o menos, en este grupo humano, es 0,9014.
Los artículos de la Serie "Estadística Aplicada a la Investigación en Salud" provienen del curso Estadística Aplicada a la Investigación en Salud. Si le interesa ahondar en estos contenidos, le invitamos tomar el curso en el siguiente link.
 Esta obra de Medwave está bajo una licencia Creative Commons Atribución-NoComercial 3.0 Unported. Esta licencia permite el uso, distribución y reproducción del artículo en cualquier medio, siempre y cuando se otorgue el crédito correspondiente al autor del artículo y al medio en que se publica, en este caso, Medwave.
Esta obra de Medwave está bajo una licencia Creative Commons Atribución-NoComercial 3.0 Unported. Esta licencia permite el uso, distribución y reproducción del artículo en cualquier medio, siempre y cuando se otorgue el crédito correspondiente al autor del artículo y al medio en que se publica, en este caso, Medwave.

En la sección Series, Medwave publica artículos relacionados con el desarrollo y discusión de herramientas metodológicas para la investigación clínica, la gestión en salud, la gesión de la calidad y otros temas de interés. En esta edición se presentan dos artículos que forman parte del programa de formación en Medicina Basada en Evidencias que se dicta por e-Campus de Medwave. El artículo siguiente pertenece a la Serie "Estadística Aplicada a la Investigación en Salud".
Autor:
Fernando Quevedo Ricardi[1]
Citación: Quevedo F. Normal distribution. Medwave 2011 May;11(05):e5033 doi: 10.5867/medwave.2011.05.5033
Fecha de envío: 6/4/2011
Fecha de aceptación: 16/4/2011
Fecha de publicación: 1/5/2011
Origen: solicitado
Tipo de revisión: sin revisión por pares
Nos complace que usted tenga interés en comentar uno de nuestros artículos. Su comentario será publicado inmediatamente. No obstante, Medwave se reserva el derecho a eliminarlo posteriormente si la dirección editorial considera que su comentario es: ofensivo en algún sentido, irrelevante, trivial, contiene errores de lenguaje, contiene arengas políticas, obedece a fines comerciales, contiene datos de alguna persona en particular, o sugiere cambios en el manejo de pacientes que no hayan sido publicados previamente en alguna revista con revisión por pares.
Nombre/name: Luis Gonzalo Higareda
Fecha/date: 2014-06-02 20:00:42
Comentario/comment:
En el articulo menciona que los fenĂłmenos dentro de las ciencias de la salud provienen de una distribuciĂłn normal por lo cual me pregunto Âżesto siempre es asĂ? o cual seria la mejor manera de comprobar que mis datos cumplen una distribuciĂłn normal.
Mi duda surge, debido a que en varios seminarios de estudiantes de licenciatura y posgrado que trabajan con muestras biológicas, a menudo la pregunta de sus tutores o revisores es si verificaron que sus datos tienen una distribución normal para por supuesto aplicar pruebas no paramétricas si es que no es asi.
De antemano agradezco sus comentarios, ya que estos nos retroalimentan.
Saludos cordiales
Para comentar debe iniciar sesión







 Estudios originales
Estudios originales