Revista Biomķdica Revisada Por Pares

En la secci¾n Series, Medwave publica artĒculos relacionados con el desarrollo y discusi¾n de herramientas metodol¾gicas para la investigaci¾n clĒnica, la gesti¾n en salud, la gesi¾n de la calidad y otros temas de interķs. En esta edici¾n se presentan dos artĒculos que forman parte del programa de formaci¾n en Medicina Basada en Evidencias que se dicta por e-Campus de Medwave. El artĒculo siguiente pertenece a la Serie "EstadĒstica Aplicada a la Investigaci¾n en Salud".
Las medidas de tendencia central son medidas estadĒsticas que pretenden resumir en un solo valor a un conjunto de valores. Representan un centro en torno al cual se encuentra ubicado el conjunto de los datos. Las medidas de tendencia central mßs utilizadas son: media, mediana y moda. Las medidas de dispersi¾n en cambio miden el grado de dispersi¾n de los valores de la variable. Dicho en otros tķrminos las medidas de dispersi¾n pretenden evaluar en quķ medida los datos difieren entre sĒ. De esta forma, ambos tipos de medidas usadas en conjunto permiten describir un conjunto de datos entregando informaci¾n acerca de su posici¾n y su dispersi¾n.
Los procedimientos para obtener las medidas estadĒsticas difieren levemente dependiendo de la forma en que se encuentren los datos. Si los datos se encuentran ordenados en una tabla estadĒstica diremos que se encuentran ōagrupadosö y si los datos no estßn en una tabla hablaremos de datos ōno agrupadosö.
Seg·n este criterio, haremos primero el estudio de las medidas estadĒsticas para datos no agrupados y luego para datos agrupados.
Promedio o media
La medida de tendencia central mßs conocida y utilizada es la media aritmķtica o promedio aritmķtico. Se representa por la letra griega Ą cuando se trata del promedio del universo o poblaci¾n y por Ȳ (lķase Y barra) cuando se trata del promedio de la muestra. Es importante destacar que Ą es una cantidad fija mientras que el promedio de la muestra es variable puesto que diferentes muestras extraĒdas de la misma poblaci¾n tienden a tener diferentes medias. La media se expresa en la misma unidad que los datos originales: centĒmetros, horas, gramos, etc.
Si una muestra tiene cuatro observaciones: 3, 5, 2 y 2, por definici¾n el estadĒgrafo serß:
Estos cßlculos se pueden simbolizar:
Donde Y1 es el valor de la variable en la primera observaci¾n, Y2 es el valor de la segunda observaci¾n y asĒ sucesivamente. En general, con ōnö observaciones, Yi representa el valor de la i-ķsima observaci¾n. En este caso el promedio estß dado por
De aquĒ se desprende la f¾rmula definitiva del promedio:
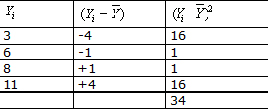
Desviaciones: Se define como la desviaci¾n de un dato a la diferencia entre el valor del dato y la media:
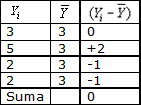
Ejemplo de desviaciones:
Una propiedad interesante de la media aritmķtica es que la suma de las desviaciones es cero.
Mediana
Otra medida de tendencia central es la mediana. La mediana es el valor de la variable que ocupa la posici¾n central, cuando los datos se disponen en orden de magnitud. Es decir, el 50% de las observaciones tiene valores iguales o inferiores a la mediana y el otro 50% tiene valores iguales o superiores a la mediana.
Si el n·mero de observaciones es par, la mediana corresponde al promedio de los dos valores centrales. Por ejemplo, en la muestra 3, 9, 11, 15, la mediana es (9+11)/2=10.
Moda
La moda de una distribuci¾n se define como el valor de la variable que mßs se repite. En un polĒgono de frecuencia la moda corresponde al valor de la variable que estß bajo el punto mßs alto del grßfico. Una muestra puede tener mßs de una moda.
Las medidas de dispersi¾n entregan informaci¾n sobre la variaci¾n de la variable. Pretenden resumir en un solo valor la dispersi¾n que tiene un conjunto de datos. Las medidas de dispersi¾n mßs utilizadas son: Rango de variaci¾n, Varianza, Desviaci¾n estßndar, Coeficiente de variaci¾n.
Rango de variaci¾n
Se define como la diferencia entre el mayor valor de la variable y el menor valor de la variable.
La mejor medida de dispersi¾n, y la mßs generalizada es la varianza, o su raĒz cuadrada, la desviaci¾n estßndar. La varianza se representa con el sĒmbolo σ▓ (sigma cuadrado) para el universo o poblaci¾n y con el sĒmbolo s2 (s cuadrado), cuando se trata de la muestra. La desviaci¾n estßndar, que es la raĒz cuadrada de la varianza, se representa por σ (sigma) cuando pertenece al universo o poblaci¾n y por ōsö, cuando pertenece a la muestra. σ▓ y σ son parßmetros, constantes para una poblaci¾n particular; s2 y s son estadĒgrafos, valores que cambian de muestra en muestra dentro de una misma poblaci¾n. La varianza se expresa en unidades de variable al cuadrado y la desviaci¾n estßndar simplemente en unidades de variable.
F¾rmulas
Donde Ą es el promedio de la poblaci¾n.
Donde Ȳ es el promedio de la muestra.
Consideremos a modo de ejemplo una muestra de 4 observaciones
Seg·n la f¾rmula el promedio calculado es 7, veamos ahora el cßlculo de las medidas de dispersi¾n:
s2 = 34 / 3 = 11,33 Varianza de la muestra
La desviaci¾n estßndar de la muestra (s) serß la raĒz cuadrada de 11,33 = 3,4.
Interpretaci¾n de la varianza (vßlida tambiķn para la desviaci¾n estßndar): un alto valor de la varianza indica que los datos estßn alejados del promedio. Es difĒcil hacer una interpretaci¾n de la varianza teniendo un solo valor de ella. La situaci¾n es mßs clara si se comparan las varianzas de dos muestras, por ejemplo varianza de la muestra igual 18 y varianza de la muestra b igual 25. En este caso diremos que los datos de la muestra b tienen mayor dispersi¾n que los datos de la muestra a. esto significa que en la muestra a los datos estßn mßs cerca del promedio y en cambio en la muestra b los datos estßn mßs alejados del promedio.
Coeficiente de variaci¾n
Es una medida de la dispersi¾n relativa de los datos. Se define como la desviaci¾n estßndar de la muestra expresada como porcentaje de la media muestral.
Es de particular utilidad para comparar la dispersi¾n entre variables con distintas unidades de medida. Esto porque el coeficiente de variaci¾n, a diferencia de la desviaci¾n estßndar, es independiente de la unidad de medida de la variable de estudio.
Se identifica como datos agrupados a los datos dispuestos en una distribuci¾n de frecuencia. En tal caso las f¾rmulas para el cßlculo de promedio, mediana, modo, varianza y desviaci¾n estßndar deben incluir una leve modificaci¾n. A continuaci¾n se entregan los detalles para cada una de las medidas.
Promedio en datos agrupados
La f¾rmula es la siguiente:
Donde ni representa cada una de las frecuencias correspondientes a los diferentes valores de Yi.
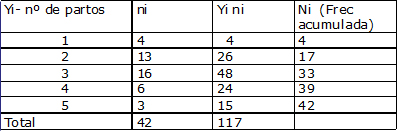
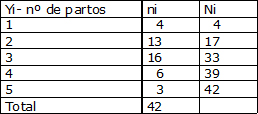
Consideremos como ejemplo una distribuci¾n de frecuencia de madres que asisten a un programa de lactancia materna, clasificadas seg·n el n·mero de partos. Por tratarse de una variable en escala discreta, las clases o categorĒas asumen s¾lo ciertos valores: 1, 2, 3, 4, 5.
Entonces las 42 madres han tenido, en promedio, 2,78 partos.
Si la variable de interķs es de tipo continuo serß necesario determinar, para cada intervalo, un valor medio que lo represente. Este valor se llama marca de clase (Yc) y se calcula dividiendo por 2 la suma de los lĒmites reales del intervalo de clase. De ahĒ en adelante se procede del mismo modo que en el ejercicio anterior, reemplazando, en la formula de promedio, Yi por Yc.
Mediana en datos agrupados
Si la variable es de tipo discreto la mediana serß el valor de la variable que corresponda a la frecuencia acumulada que supere inmediatamente a n/2. En los datos de la tabla 1 Me=3, ya que 42/2 es igual a 21 y la frecuencia acumulada que supera inmediatamente a 21 es 33, que corresponde a un valor de variable (Yi) igual a 3.
Si la variable es de tipo continuo es necesario, primero, identificar la frecuencia acumulada que supere en forma inmediata a n/2, y luego aplicar la siguiente f¾rmula:
Donde:
Moda en datos agrupados
Si la variable es de tipo discreto la moda o modo serß al valor de la variable (Yi) que tenga la mayor frecuencia absoluta ( ). En los datos de la tabla 1 el valor de la moda es 3 ya que este valor de variable corresponde a la mayor frecuencia absoluta =16.
Mßs adelante se presenta un ejemplo integrado para promedio, mediana, varianza y desviaci¾n estßndar en datos agrupados con intervalos.
Varianza en datos agrupados
Para el cßlculo de varianza en datos agrupados se utiliza la f¾rmula
Con los datos del ejemplo y recordando que el promedio (Y) result¾ ser 2,78 partos por madre,
Cuando los datos estßn agrupados en intervalos de clase, se trabaja con la marca de clase (Yc), de tal modo que la f¾rmula queda:
Donde Yc es el punto medio del intervalo y se llama marca de clase del intervalo
Yc= (LĒmite inferior del intervalo + limite superior del intervalo)/2.
Los percentiles son valores de la variable que dividen la distribuci¾n en 100 partes iguales. De este modo si el percentil 80 (P80) es igual a 35 a±os de edad, significa que el 80% de los casos tiene edad igual o inferior a 35 a±os.
Su procedimiento de cßlculo es relativamente simple en datos agrupados sin intervalos.
Retomemos el ejemplo de la variable n·mero de partos:
El percentil j (Pj) corresponde al valor de la variable (Yi ) cuya frecuencia acumulada supera inmediatamente al ōjö % de los casos (jxn/100).
El percentil 80, en los datos de la tabla, serß el valor de la variable cuyo Ni sea inmediatamente superior a 33,6 ((80x42) /100).
El primer Ni que supera a 33,6 es 39. Por lo tanto al percentil 80 le corresponde el valor 4. Se dice entonces que el percentil 80 es 4 partos (P80=4). Este resultado significa que un 80% de las madres estudiadas han tenido 4 partos o menos.
Si los datos estßn agrupados en una tabla con intervalos, el procedimiento es levemente mßs complejo ya que se hace necesaria la aplicaci¾n de una f¾rmula.
Se aplica a los datos del intervalo cuya frecuencia acumulada ( Ni ) sea inmediatamente superior al ōjö % de los casos (jxn/100).
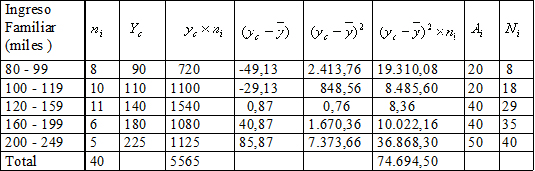
En la siguiente tabla se muestra la distribuci¾n de 40 familias seg·n su ingreso mensual en miles de pesos. N¾tese que para calcular el centro de clase se usaron los lĒmites reales de cada intervalo.
1. El ingreso mensual promedio serß:
2. La mediana serß:
Esto significa que un 50% de las familias tiene ingreso mensual igual o inferior a $127.270.
3. El percentil 78 serß:
Por lo tanto se puede decir que 78% de las familias tienen ingreso igual o inferior a $174.660.
4. Los percentiles 10 y 90 serßn:
A base de los valores de los percentiles 10 y 90 se pueden hacer tres afirmaciones:
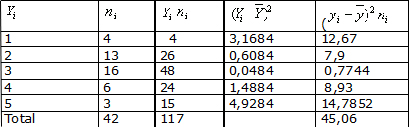
5. - La varianza serß:
6. La desviaci¾n estßndar es la raĒz cuadrada de esta cifra, es decir: 43,76.
Los artículos de la Serie "Estadística Aplicada a la Investigación en Salud" provienen del curso Estadística Aplicada a la Investigación en Salud. Si le interesa ahondar en estos contenidos, le invitamos tomar el curso en el siguiente link.

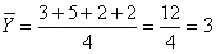
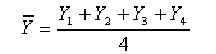
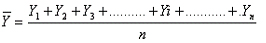
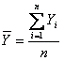
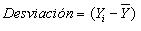
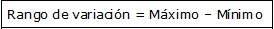
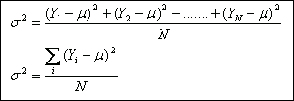
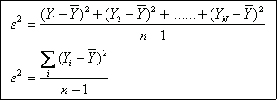
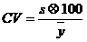
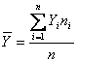
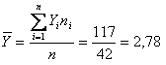
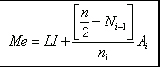

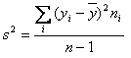
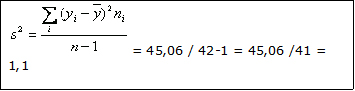
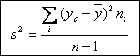
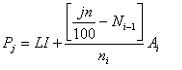
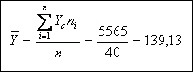
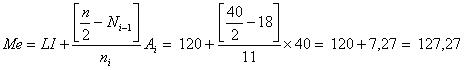
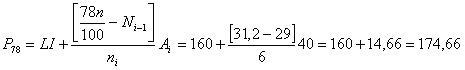
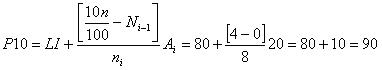
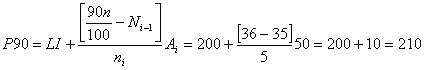
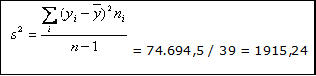
 Esta obra de Medwave estß bajo una licencia Creative Commons Atribuci¾n-NoComercial 3.0 Unported. Esta licencia permite el uso, distribuci¾n y reproducci¾n del artĒculo en cualquier medio, siempre y cuando se otorgue el crķdito correspondiente al autor del artĒculo y al medio en que se publica, en este caso, Medwave.
Esta obra de Medwave estß bajo una licencia Creative Commons Atribuci¾n-NoComercial 3.0 Unported. Esta licencia permite el uso, distribuci¾n y reproducci¾n del artĒculo en cualquier medio, siempre y cuando se otorgue el crķdito correspondiente al autor del artĒculo y al medio en que se publica, en este caso, Medwave.
En la secci¾n Series, Medwave publica artĒculos relacionados con el desarrollo y discusi¾n de herramientas metodol¾gicas para la investigaci¾n clĒnica, la gesti¾n en salud, la gesi¾n de la calidad y otros temas de interķs. En esta edici¾n se presentan dos artĒculos que forman parte del programa de formaci¾n en Medicina Basada en Evidencias que se dicta por e-Campus de Medwave. El artĒculo siguiente pertenece a la Serie "EstadĒstica Aplicada a la Investigaci¾n en Salud".
Autor:
Fernando Quevedo Ricardi[1]
Citaci¾n: Quevedo F. Measures of central tendency and dispersion. Medwave 2011 Mar;11(3):e4934 doi: 10.5867/medwave.2011.03.4934
Fecha de envĒo: 6/1/2011
Fecha de aceptaci¾n: 14/1/2011
Fecha de publicaci¾n: 2/3/2011
Origen: solicitado
Tipo de revisi¾n: sin revisi¾n por pares
Nos complace que usted tenga interķs en comentar uno de nuestros artĒculos. Su comentario serß publicado inmediatamente. No obstante, Medwave se reserva el derecho a eliminarlo posteriormente si la direcci¾n editorial considera que su comentario es: ofensivo en alg·n sentido, irrelevante, trivial, contiene errores de lenguaje, contiene arengas polĒticas, obedece a fines comerciales, contiene datos de alguna persona en particular, o sugiere cambios en el manejo de pacientes que no hayan sido publicados previamente en alguna revista con revisi¾n por pares.
A·n no hay comentarios en este artĒculo.
Para comentar debe iniciar sesi¾n







 Estudios originales
Estudios originales