Revista Biomédica Revisada Por Pares

 Para Descargar PDF debe Abrir sesión.
Para Descargar PDF debe Abrir sesión.
Palabras clave: observational study, case-control studies, bias, epidemiology, biostatistics
Los estudios de casos y controles han sido esenciales en el desarrollo de la epidemiología y de la salud pública. En este diseńo, el análisis de los datos se realiza desde el desenlace hacia la exposición, es decir, retrospectivamente, ya que se estudia la asociación entre factores de exposición y un desenlace conocido entre personas que ya presentan una condición (casos) y quienes no la presentan (controles). Por lo tanto, son muy útiles en condiciones infrecuentes o que requieren una larga latencia para ocurrir. Existen distintas metodologías de selección de casos, pero el aspecto central es la adecuada selección de controles. La recolección de los datos puede ser retrospectiva (desde de registros clínicos) o prospectiva (mediante la aplicación de instrumentos de recolección de datos a los participantes). En función del objetivo del estudio, se dispone de distintos tipos de estudios de casos y controles, pero todos presentan una vulnerabilidad particular al sesgo de información y de confusión, los que pueden controlarse a nivel del diseńo y del análisis estadístico. En este artículo se abordan conceptos teóricos generales sobre los estudios de casos y controles, considerando aspectos históricos, metodología de selección de participantes, tipos estudios de casos y controles, medidas de asociación, potenciales sesgos, ventajas y desventajas. Finalmente, se discuten algunos conceptos de relevancia sobre este diseńo para los estudiantes de pre y posgrado de ciencias de la salud. Esta revisión es la tercera entrega de una serie metodológica sobre conceptos generales en bioestadística y epidemiología clínica desarrollada por la Cátedra de Metodología de la Investigación Científica de la Escuela de Medicina de la Universidad de Valparaíso, Chile.
|
Ideas clave
|
Durante el siglo XIX, ciertas investigaciones ya incluían algunos elementos del diseño de casos y controles. Probablemente, el ejemplo modélico es el de la historia de John Snow y el Reverendo Henry Whitehead con sus investigaciones sobre los brotes de cólera en relación con la fuente de Broad Street[1],[2]. A diferencia de Snow, Whitehead se dedicó a evaluar la exposición a agua de la fuente en individuos sin cólera (controles). Mediante una encuesta acuciosa y sistemática, que incluía visitar a una persona hasta cinco veces, recopiló información básica pero relevante respecto del consumo de agua entre residentes de Broad Street, concluyendo que el uso del agua de la fuente se asociaba con la presencia de cólera, lo que repercutió en una disminución de 127 muertes el 2 de septiembre de 1854 a 30 el día 8 de septiembre[3].
Sin embargo, la concepción moderna del diseño de casos y controles se reconoce en el estudio sobre factores asociados al cáncer de mama de Janet Lane-Claypon en 1926[4]. En 1939, otro estudio de casos y controles encabezado por Franz Müller[5], miembro del partido Nazi, vinculaba el consumo de cigarrillos con el cáncer de pulmón, lo que iba en concordancia con el sentimiento antitabaco de Hitler. En efecto, durante su gobierno se promovieron campañas propagandísticas en contra del consumo de tabaco a la luz de la reciente evidencia disponible en cuanto a sus efectos. Müller envió un cuestionario a familiares de víctimas del cáncer pulmonar, preguntando acerca del patrón de consumo, su forma y temporalidad, además del tipo de tabaco usado, corroborando una fuerte asociación entre el consumo de tabaco y la enfermedad[5],[6]. A continuación, y paralelo al curso de la Segunda Guerra Mundial, hubo un detenimiento teórico en el desarrollo de este diseño metodológico hasta 1950, año en que se publicaban cuatro estudios de casos y controles que analizaban la relación entre tabaquismo y cáncer pulmonar, validando su uso en el estudio de la etiología de las enfermedades. Uno de ellos es el estudio desarrollado por Richard Doll y Austin Bradford Hill[7],[8], quienes argumentaban que el aumento en las tasas de cáncer pulmonar observados en Gales e Inglaterra, no se explicaba completamente por un mayor desarrollo de la calidad de las pruebas diagnósticas, como se esgrimía en la época, sino que a factores ambientales como el tabaquismo y la polución ambiental7.
Unas décadas más tarde, en 1987, se publicaba un estudio sobre los factores asociados a la transmisión del síndrome de inmunodeficiencia adquirida, tales como la promiscuidad y el uso de drogas endovenosas[9],[10]. El conocimiento de estos factores de riesgo permitió la implementación de medidas que redujeron la transmisión del virus, incluso antes de que fuese identificado[10].
De este modo, la epidemiología comenzaba a priorizar el análisis de factores de riesgo por sobre el estudio de causas suficientes y necesarias[1], pues ya Snow había declinado en la búsqueda de un agente microscópico para el cólera, poniendo en primer lugar el esclarecer las vías en que la enfermedad se transmitía de persona a persona[3]. De este modo, para estudiar la etiología y los factores pronósticos (factores protectores y factores de riesgo), la epidemiología observacional ha desarrollado los estudios de casos y controles y los estudios de cohorte[11]. En esta revisión nos centraremos en el primer diseño, pues el análisis de los estudios de cohorte corresponderá al siguiente artículo de esta serie metodológica.
Este artículo corresponde a la tercera entrega de una serie metodológica de seis revisiones narrativas acerca de tópicos generales en bioestadística y epidemiología clínica, las que explorarán artículos publicados disponibles en las principales bases de datos y textos de consulta especializados. La serie está orientada a la formación de estudiantes de pre y posgrado, y es realizada por la Cátedra de Metodología de la Investigación Científica de la Escuela de Medicina de la Universidad de Valparaíso, Chile. Por lo tanto, el objetivo de este manuscrito es abordar los principales conceptos teóricos y prácticos de los estudios de casos y controles.
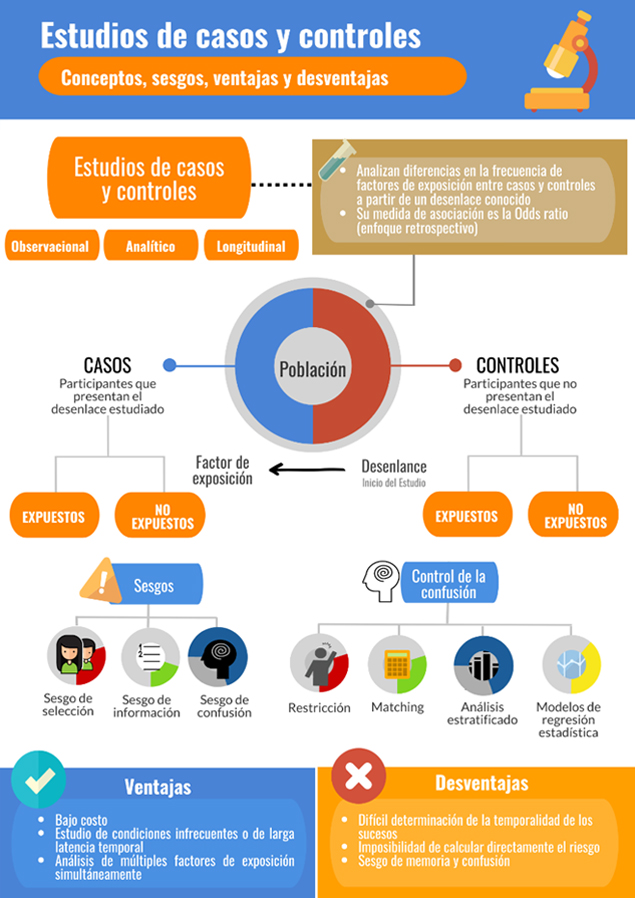
Los estudios de casos y controles constituyen un diseño observacional, analítico y longitudinal: el investigador no interviene la variable de exposición, el diseño permite la realización de pruebas de hipótesis estadística y existe un seguimiento en el tiempo de los individuos y variables de interés. Incluso, algunos autores plantean que podrían demostrar relaciones causales más allá de meras asociaciones entre variables[12], siendo esto un motivo controvertido. Para su realización, se recluta a un grupo de participantes que presentan un desenlace de interés, usualmente una enfermedad (casos), y a un grupo que no lo presenta (controles), similares en sus características basales. En ambos conjuntos se estudian variables conceptualizadas como factores de riesgo y se compara su nivel de exposición. Entonces, una característica fundamental de un estudio de casos y controles es que los sujetos son seleccionados según el desenlace, lo que reviste una ventaja al pensar que no es necesario esperar un gran espacio de tiempo para que ocurra el fenómeno que se quiere estudiar, pero al mismo tiempo una desventaja, ya que muchas veces los datos tendrán que recogerse también retrospectivamente, por lo que su calidad dependerá de un adecuado registro y aun de la memoria de los participantes[13].
Selección de los casos
La selección de los casos debe ser rigurosa, privilegiando los casos incidentes (casos que hayan sido diagnosticados recientemente) por sobre los casos prevalentes (casos que lleven un largo tiempo de diagnóstico), puesto que los casos incidentes son más similares y consistentes con la realidad actual que aquellos casos antiguos, donde por ejemplo, los criterios diagnósticos podrían haber sido otros.
En este sentido, es necesario contar con una definición clara del desenlace a estudiar (por ejemplo, criterios diagnósticos internacionales y actuales, exámenes de laboratorio, estudios imagenológicos, entre otros) y de los otros criterios de inclusión y exclusión, tales como lugar de selección (por ejemplo, servicio hospitalario o ciudad desde la cual se obtuvo a los participantes) y rango etario[14],[15].
Según su lugar de obtención, encontramos casos hospitalarios, casos poblacionales o comunitarios y casos de grupos especiales (por ejemplo, desde agrupaciones como Alcohólicos Anónimos o sociedades de pacientes con alguna enfermedad genética). Los casos hospitalarios pudiesen ser fáciles de conseguir, pues se emplea el registro de personas ya existente en un centro de salud; sin embargo, podrían no ser representativos del grupo de personas con la enfermedad. Por su parte, los casos poblacionales son infrecuentes debido a la dificultad que implica encontrarlos sin contar con registros clínicos, como sucede la mayoría de las veces, pero ventajosamente se disminuiría el sesgo de selección y mejoraría la validez interna y la capacidad de generalización de los resultados, ya que la selección comunitaria sería cercana a lo que sucede realmente con la patología[16].
Selección de los controles
La selección de controles corresponde al hito más importante del desarrollo de un estudio de casos y controles, pues en ella descansa la validez interna de la investigación. Los controles representan la frecuencia basal de exposición en individuos libres del desenlace en estudio. Sin embargo, no necesariamente deben ser absolutamente sanos, pues una persona enferma por otra causa puede desarrollar igualmente la condición de interés[17]. Lo fundamental es que estén libres del desenlace en estudio y su selección debe siempre realizarse independientemente de la presencia o no del factor de exposición que se analiza.
Los controles deben ser representativos de la población desde la cual se obtuvo a los casos, es decir, deben extraerse desde la misma base poblacional (regla conocida como “principio de base del estudio”)[16], de modo de presentar el mismo riesgo de exposición que los casos y evitar el sesgo de selección. La mejor forma de garantizarlo es seleccionarlos mediante un muestreo aleatorio, lo que aseguraría que los controles hayan tenido la misma probabilidad teórica que los casos de haber estado expuestos al factor de riesgo[18]. La cantidad de controles por cada caso no debería exceder a tres o cuatro, pues se ha demostrado que por sobre esta cantidad el incremento de la potencia del estudio es mínima pero el de costos es desproporcionado[17],[19]. Lo anterior responde al “principio de eficiencia”, tanto estadística (lograr una potencia adecuada) como operacional (optimizar el uso del tiempo, energía y recursos de la investigación)[16].
Los controles pueden hallarse en un grupo conocido, esto es un grupo observado durante un periodo. No obstante, el grupo del que provienen los casos es usualmente desconocido[20], por lo que su determinación puede ser previa a la delimitación del grupo desde donde se seleccionarán los participantes.
En este sentido, como no se conoce la base poblacional de los casos, la selección de los controles sucedería igualmente desde un grupo desconocido. Para ello se han sugerido algunas estrategias, como el seleccionar controles que sean vecinos del lugar de residencia de los casos[17]. Asimismo, se ha propuesto que los controles puedan ser amigos (compartirían características como el nivel socioeconómico y educacional) o familiares de los casos (compartirían características genéticas y de estilos de vida). La selección puede hacerse también a partir de controles hospitalarios, lo que es conveniente si se piensa que provendrían desde el mismo centro de salud de los casos y además tendrían motivación por participar debido a una conducta similar en cuanto a la búsqueda de cuidado en su salud mayor al de los controles obtenidos desde la comunidad[20]. No obstante, una desventaja es que no podría asegurarse que los controles hospitalarios tengan una probabilidad similar que los casos de haber estado expuestos al factor que se está analizando[17].
Una vez seleccionados los casos y los controles, debe determinarse la proporción de exposición a los factores de riesgo estudiados en ambos grupos. Estos datos pueden determinarse al revisar las fichas clínicas de los participantes del estudio o también mediante la aplicación de cuestionarios. Es de suma relevancia, para no incurrir en sesgos como se analizará más adelante, el que los datos se busquen con la misma acuciosidad en casos y controles. Finalmente, y como es de esperar, en la medida de que la diferencia en la proporción de expuestos a un factor de riesgo entre los grupos sea mayor, mayor será también la probabilidad de que exista una asociación entre el desenlace y dicho factor[11].
Medidas de asociación
Por la naturaleza del diseño de casos y controles, la medida de asociación se estima en relación con un evento ya ocurrido, comparándose la frecuencia de exposición entre casos y controles, además de otros estimadores. Debido a esta naturaleza retrospectiva del evento, no es posible calcular el riesgo relativo, sino que se estima la Odds ratio (también conocida como razón de momios, razón de probabilidades, razón de ventajas, razón de disparidad, razón de productos cruzados, entre otros), asociada a sus intervalos de confianza[10].
Esta medida representa el cociente entre la chance (Odds ratio) de exposición en el grupo de casos y en el grupo de controles, interpretada como cuántas veces más posibilidades tienen los casos de haber estado expuestos al factor estudiado en comparación con los controles (debe interpretarse de esta manera y no como un riesgo relativo directo)[16]. No obstante, la Odds ratio es una buena estimación del riesgo relativo cuando la tasa de incidencia del desenlace en estudio es baja (no mayor a 5 o10% tanto en expuestos como no expuestos), lo que se ha conocido como el supuesto de enfermedad rara (rare disease assumption)[16].
La Odds ratio tiene una interpretación similar (pero no igual) al riesgo relativo, tomando valores que van del cero al infinito. Una Odds ratio menor a 1 indica que la exposición se comporta como un factor protector para presentar el desenlace, mientras que si fuera mayor a 1 se trataría un factor de riesgo, es decir, aumenta la probabilidad de que el desenlace ocurra. Finalmente, si su valor fuera igual a 1, podría deducirse que no existe asociación entre el factor de exposición y el desenlace[21] (Ejemplo 1)[1].
|
Ejemplo 1. En el estudio sobre cólera y consumo del agua de la fuente de Broad Street y a partir de los datos obtenidos por Whitehead, se concluyó que la Odds ratio para uso del agua de la fuente y cólera fue de 19,6. Es decir, el beber agua de la fuente es un factor de riesgo (Odds ratio mayor a 1). Esto se puede interpretar como sigue: aquellos que presentaron cólera (casos) tuvieron una posibilidad 19,6 veces mayor de haber bebido agua de la fuente (lectura retrospectiva) que aquellos que no presentaron cólera (controles). |
Mediante el diseño de casos y controles no puede calcularse directamente la incidencia ni la prevalencia de una condición. No obstante, una excepción serían los estudios de casos y controles poblacionales, donde se reconoce que la prevalencia de exposición del grupo control es representativa de toda la población y la incidencia poblacional de la variable a estudiar es conocida, lo que permitiría la estimación de la incidencia. Esta estimación sería posible en estudios de casos y controles anidados en una cohorte y en estudios de casos-cohorte[15], diseños que se definirán a continuación.
En la literatura existen múltiples variantes de los diseños metodológicos tradicionales que pueden satisfacer de mejor manera las necesidades y las posibilidades de la investigación y del investigador. A continuación, se refieren las principales características de algunas variantes según el método de selección de casos.
Estudios de casos y controles basados en casos
Este diseño corresponde a la forma tradicional y más frecuente de un estudio de casos y controles. Se reclutan casos ya existentes (casos prevalentes) o nuevos (casos incidentes), conformando un grupo control a partir de la misma base o cohorte hipotética (hospitalaria o poblacional)[16].
Estudio de casos y controles anidados en cohorte
En este diseño, el muestreo de casos se realiza desde una cohorte, es decir, desde un estudio prospectivo en donde todos los participantes se encontraban inicialmente sin el desenlace de interés. Una vez que lo presentan, se transforman en casos incidentes que pueden nutrir a un estudio de casos y controles anidado, para luego efectuar el análisis de los factores a los que estuvo expuesto cada grupo. Paralelamente, los controles provienen desde la misma cohorte y se seleccionan mediante un muestreo aleatorio, realizando un emparejamiento de acuerdo con la duración de seguimiento. Este tipo de estudio es conveniente por contemplar un mejor control de los factores de confusión, pues la cohorte constituye un grupo homogéneo definido en espacio y en tiempo. Esto significa que la plataforma desde la cual se obtienen los participantes es bien conocida. También, permite una mejor cuantificación de los efectos de las exposiciones dependientes del tiempo, ya que se sabe con mayor precisión cuándo se presentó el desenlace[15],[18].
Estudios de casos cruzados, caso-caso o autocontrolados (case-crossover studies)
En este diseño metodológico de reciente desarrollo, los antecedentes de exposición de cada paciente se usan para su propio control, lo que pretende eliminar las diferencias interpersonales que generan confusión[22]. Esto es, cada caso es su propio control[23], por lo que se trata de un tipo de diseño pareado[24]. Estos estudios son útiles en el análisis de exposiciones transitorias, tales como un periodo de mal dormir como factor de riesgo para sufrir un accidente automovilístico[23], donde se definiría un “periodo de caso”, que puede comprender las 48 horas previas al accidente, y un “periodo control”, que podría abarcar entre las 72 y las 49 horas previas. Una desventaja importante es que este modelo supone que no existe un efecto de continuación de la variable de exposición una vez que ha cesado (carry-over).
Estudios de casos-cohorte
Corresponde a un diseño mixto, que involucra características de un estudio de casos y controles y de un diseño de cohorte, no obstante, es más cercano metodológicamente a este último[25]. Los estudios de casos-cohorte se analizarán en la próxima entrega de esta serie metodológica, que corresponde a estudios de cohorte.
En los estudios de casos y controles, la característica que condiciona de forma más importante a la aparición de sesgos es que el análisis se inicia desde el desenlace y no desde la exposición, obteniéndose la información mayoritariamente de manera retrospectiva. Igualmente, deben considerarse sesgos a los que puede incurrirse durante la planificación del estudio, como el subvalorar el costo económico del estudio, lo que puede imposibilitar una apropiada finalización[26].
Sesgo de selección
El sesgo de selección se asocia a una ausencia de comparabilidad (falta de similitud) entre los grupos estudiados. Es decir, los casos y los controles difieren en sus características basales, medidas o no medidas, debido al método en que son seleccionados. Por ende, es necesario asegurar que los casos y los controles sean similares en todas las características importante excepto en el desenlace estudiado[27]. Un ejemplo es el sesgo de Berkson, también conocido como sesgo de admisión, paradoja o falacia de Berkson[26],[27]. Éste resulta de una diferencia sistemática en la selección de casos hospitalarios, ya que en ocasiones la combinación entre un factor de exposición y el desenlace estudiado hace variar el riesgo de ingreso a un hospital (Ejemplo 2)[28].
|
Ejemplo 2. La hipoacusia congénita no cuenta con un tamizaje universal, pero sí se evalúa en recién nacidos menores a 32 semanas a quienes además se indica hospitalización. Sin embargo, se ha corroborado que el 50% de los casos de hipoacusia congénita se observa en recién nacidos sin factores de riesgo. Por tanto, si se realizara un estudio de casos y controles a partir de participantes hospitalarios, los casos de hipoacusia congénita en recién nacidos de término se verían subrepresentados. |
Otro tipo de sesgo de selección es el sesgo de Neyman[26],[27], también llamado de prevalencia, de incidencia o de sobrevida. Aparece cuando una determinada condición produce muertes prematuras que impiden que estos participantes puedan incorporarse al grupo de casos, lo que puede redundar en que no se obtenga una asociación debido a la falta de incorporación en el análisis de los participantes que ya han muerto. Por lo tanto, se genera un grupo de casos que no es representativo de los casos comunitarios. Esto es lo que ocurre con enfermedades que son rápidamente fatales, subclínicas o transitorias (Ejemplo 3).
|
Ejemplo 3. Se estudia la relación entre hipertensión arterial (factor de riesgo) y accidente cerebrales vasculares (desenlace). No obstante, es posible que el análisis se vea sesgado por la no inclusión de sujetos que murieron por causa del accidente cerebral vascular, lo que disminuiría la probabilidad de hallar una asociación entre el factor de riesgo y el desenlace. |
Sesgo de información
También denominado sesgo de observación, clasificación o medición. Aparece cuando hay una determinación incorrecta de la exposición o del desenlace[27]. En los estudios de casos y controles, la información sobre la exposición debe recabarse de la misma manera en ambos grupos (lo que se conoce como “principio de precisión comparable”[16]) e idealmente por personas entrenadas y que no conozcan a qué grupo pertenecen los respondedores, ya que de saberlo, pueden provocar que cierta información sea respondida diferencialmente entre grupos, lo que se ha conocido como sesgo del entrevistador[14].
Un tipo de sesgo de información de gran importancia en este diseño es el sesgo de memoria o de recuerdo, debido a que los datos muchas veces provendrán desde el recuerdo que tengan los participantes de la exposición. Los casos tienden a buscar en su memoria los factores que puedan haber causado su enfermedad, pero los controles no tienen esta motivación, por lo que suele referirse que los casos recuerdan de mejor manera que los controles[17].
Como solución se ha propuesto que se seleccionen controles con enfermedades similares a la de estudio; por ejemplo, si el grupo de casos tiene el cáncer A, los controles podrían tener el cáncer B, de modo de que ambos grupos estén familiarizados y sensibilizados con la información que se recabará. Este procedimiento es válido siempre y cuando se corrobore que la exposición en estudio no se relaciona con la patología presente en el grupo control, pues de lo contrario se sumaría aun más sesgo. Otros métodos recomendados son el uso de fotografías, calendarios, periódicos o cualquier material que ayude a clarificar los recuerdos de la exposición en los participantes[10].
Sesgo de confusión
El fenómeno de confusión ya ha sido discutido en dos artículos previos de esta serie metodológica[29],[30]. Se nombrarán estrategias de control de la confusión a nivel del diseño metodológico (restricción y matching) y del análisis estadístico (análisis estratificado, regresión estadística y puntaje de propensión).
El procedimiento de restricción corresponde a la selección estricta de sujetos que presenten la característica que se quiere “neutralizar” o bien que no la presenten. Si bien ayudaría a aumentar la validez interna (por disminuir la probabilidad de sesgo), disminuiría su validez externa, ya que los resultados serían más difíciles de extrapolar[27].
Otro modo de aminorar el efecto de la confusión es el pareo, emparejamiento o matching. Comprende la selección de participantes que comparten la característica que se busca neutralizar, por ejemplo, nivel socioeconómico o grupo etario[31]. Tal sería el caso de un estudio que busque comparar a un grupo de mujeres con y sin esclerosis múltiple. Si la primera participante es portadora de la enfermedad, tiene 40 años y es de un estrato socioeconómico alto, el control correspondiente sería una mujer de las mismas características, pero sin la enfermedad. Esto se detalla en el Ejemplo 4, a partir de las investigaciones de Lane-Claypon[4],[6] y de Müller[5].
|
Ejemplo 4. En el estudio de Franz Müller sobre consumo tabaco y su asociación con cáncer pulmonar, se reclutó a un grupo control del mismo tamaño, sexo y rango etario, para parear con un grupo de 86 pacientes con la patología. De la misma manera, Janet Lane-Claypon seleccionó 500 casos de mujeres con cáncer de mama y 500 controles sin la enfermedad, a partir de contextos hospitalarios y no hospitalarios en Glasgow y Londres. Todas las participantes fueron similares en rango etario y estrato socioeconómico. El estudio demostró que la fertilidad entre los casos fue 22% menor en comparación con las mujeres sanas, lo que sentó las primeras bases sólidas que apuntaban que la baja fertilidad aumentaba el riesgo de cáncer de mama. Los autores buscaron “neutralizar” las características que pudieran “confundir la asociación” por no encontrarse en la vía causal de la patología. De esta manera, se aproximarían al ideal teórico de que lo único que diferenciara a casos de controles fuera la presencia del cáncer pulmonar y mamario, respectivamente. |
Hay que tener en mente algunos aspectos dificultados por el matching: impedirá el análisis del efecto de las variables que se hayan pareado[27] y puede incrementar el tiempo y el costo del estudio cuando no se encuentran los controles apropiados para los casos[32]. Por tanto, el emparejamiento debe realizarse en virtud de una variable que se catalogue como un potencial factor de confusión, ya que de no ser así, se pierde eficiencia y se disminuye la validez de la comparación entre casos y controles, fenómeno conocido como sobre emparejamiento (overmatching)[33], perdiendo la opción de detectar diferencias que debieron haber sido detectadas. Por lo tanto, se ha sugerido que el emparejamiento no sea un proceso obligatorio en los estudios de casos y controles, considerándose sobre todo en caso de muestras muy pequeñas o de exposiciones muy raras[16].
El análisis estratificado puede entenderse como una forma post hoc de restricción, ya que el estudio de las variables puede estratificarse según distintos niveles de una eventual variable de confusión. Esto es demostrado en la paradoja de Simpson[16], la que muestra que la medida de asociación (Odds ratio) entre exposición y desenlace es diferente cuando se compara al grupo completo que al comparar a estratos o subconjuntos del grupo de casos y del grupo de controles definidos en función de una característica, como rango etario, sexo, entre otros, por lo que podría suponerse que la variable de estratificación puede actuar como factor confusional.
El análisis estadístico de la estratificación corresponde al procedimiento de Mantel-Haenszel, el que determina si existe asociación entre un factor de exposición y un desenlace controlando el efecto de uno o más factores de confusión. Si el efecto ajustado por el método de Mantel-Haenszel difiere significativamente del efecto “crudo” o no ajustado, se presume que el factor de confusión está presente[14],[27]. La estratificación podría verse limitada por el tamaño muestral, puesto que, al analizar diversos estratos por separado, cada grupo podría conformarse por un número muy reducido de observaciones. Un caso de análisis estratificado se cita en el Ejemplo 5.
|
Ejemplo 5. Se ha reconocido que una consecuencia de los accidentes cerebrales vasculares es la disfagia, por lo que en un servicio de neurorrehabilitación se decide la colocación de sonda nasogástrica a todos los pacientes con accidentes cerebrales vasculares para evitar la neumonía por aspiración. En efecto, la Odds ratio de tener disfagia si se tuvo un accidente cerebral vascular, resultó en 1,6 con un intervalo de confianza de 95%: 1,2 a 2,1. Se decide hacer un análisis estratificado de los pacientes con accidente cerebral vascular y disfagia según un estrato A (usuarios de sonda nasogástrica) y estrato B (no usuarios de sonda nasogástrica por indicación de retiro tras evaluación de otorrinolaringología). En el estrato A, la Odds ratio de tener disfagia si se tuvo un accidente cerebral vascular fue de 2,0 con un intervalo de confianza de 95%: 1,4 a 3,0, mientras que en el estrato B fue de 1,3 con un intervalo de confianza de 95%: 0,8 a 1,8. De acuerdo con estos resultados, la Odds ratio cruda señalaba una asociación significativa entre el haber presentado un accidente cerebral vascular y el tener disfagia, actuando el accidente cerebral vascular como un factor de riesgo (Odds ratio > 1). No obstante, solo la Odds ratio para el estrato A fue estadísticamente significativa (el intervalo de confianza no incluía al número 1). Finalmente, como parte del análisis de Mantel-Haenzsel, se calcula una Odds ratio combinada entre las Odds ratio de los estratos A y B (Odds ratio ajustada), la que resulta en 1,1 con un intervalo de confianza de 95%: 0,8 a 1,5. Se concluye que el antecedente de accidente cerebral vascular no se asocia significativamente con presentar disfagia, luego de controlar por uso de sonda nasogástrica, variable que se considera de confusión. |
Como ha sido referido en entregas previas de esta serie[29],[30], las variables de confusión pueden identificarse también mediante modelos multivariados de regresión estadística. Su objetivo es ajustar un modelo de predicción para una variable dependiente a partir del efecto de múltiples variables independientes[34],[35].
Finalmente, en estudios observacionales se ha aplicado el puntaje de propensión (propensity score)[36], una metodología estadística cuya finalidad es reducir la confusión por indicación (sesgo de selección)[37]. Este puntaje corresponde a la probabilidad de exposición a un factor estimado a partir de un conjunto de variables observadas que pueden influenciar la probabilidad de exposición (a mayor puntaje, mayor será la probabilidad de exposición). De este modo, los subgrupos de análisis pueden categorizarse en función de este puntaje o, en modelos de regresión estadística multivariados, el puntaje de propensión puede incluirse como una covariable del modelo[35]. Es importante contemplar que, pese a los procedimientos llevados a cabo en el diseño y el análisis de un estudio, puede persistir algún nivel de confusión residual no conocida, particularmente si se trata de estudios observacionales[31].
Los estudios de casos y controles constituyen el mejor diseño epidemiológico para investigar enfermedades infrecuentes y que se expresan en brotes (tal como el estudio sobre cólera asociado a la fuente de Broad Street). Suelen conducirse con rapidez, puesto que los desenlaces ya ocurrieron, obteniéndose resultados relevantes en un tiempo breve[10]. En este sentido, son útiles en patologías de larga latencia o incubación, ya que en un estudio de cohorte, por ejemplo, se requeriría de un largo periodo de tiempo para observar la aparición de la enfermedad. Otro aspecto bastante positivo es el que posibilitan el estudio de distintos factores de riesgo simultáneamente[11].
Una dificultad central es lo complejo que puede ser llegar a determinar la temporalidad de los sucesos, vale decir, si la causa precedió al efecto, como sería esperable. Pueden no detectar a pacientes que aún se encuentran incubando la patología y que han sido seleccionados como controles. Debido a la naturaleza retrospectiva de la secuencia de eventos, este tipo de estudios no permite calcular directamente el riesgo, puesto que solo puede definirse la proporción de personas con el desenlace que estuvieron expuestos en el pasado. Adicionalmente, cierto tipo de sesgos, como el de memoria, son particularmente prominentes[10],[14].
La lectura de un estudio de casos y controles debe hacerse de manera concienzuda, pues puede resultar poco intuitivo el pensar en una asociación teniendo como punto de partida el desenlace y no los factores que la habrían desencadenado: la lectura de un artículo de casos y controles se inicia al finalizar la cadena de causalidad. Esto ha provocado que el diseño de casos y controles sea clasificado como “retrospectivo”, lo que para algunos autores sería inadecuado. Esto debido a que la información también puede recogerse prospectivamente por medio de la aplicación de instrumentos, de entrevistas o de otros métodos que apunten a la “reconstrucción de los hechos”, aunque el desenlace ocurrió en el pasado y la recolección de la información se realice por lo general retrospectivamente (historia clínica, bases de datos, entre otros). Por lo tanto, un estudio de casos y controles podría ser prospectivo desde el punto de vista de cómo se obtienen los datos, por lo que hay que clarificar si la clasificación temporal (retrospectivo o prospectivo) se hizo en función del diseño o de la recogida de datos[16].
Aunque se ha propuesto que para la selección de casos las definiciones diagnósticas deben ser claras y deben quedar refrendadas en los criterios de elegibilidad, debe tenerse en cuenta que múltiples y muy estrictos criterios de inclusión y de exclusión limitarán la validez externa o “generalizabilidad” de los resultados. Sin embargo, el estudio debe realizarse sobre la premisa de que la validez interna ocupa un lugar prioritario por sobre la validez externa, ya que la segunda depende de la primera[16].
Respecto a los controles, y aunque algunos autores han apoyado la idea de usar dos grupos de controles para un grupo de casos y luego, tras el análisis de datos, elegir el que presente las mejores características[17],[38], lo fundamental, más allá de la cantidad de grupos, es el elegir de la mejor manera posible a los controles: deben ser similares en todos los aspectos importantes a los casos a excepción de no portar la condición que se está estudiando. La elección de controles es fundamental, por lo que algunos autores han indicado que no deben aceptarse los resultados de un estudio de casos y controles hasta que el lector haga una evaluación de la rigurosidad con que con el grupo control fue seleccionado[14]. Para esto, la investigación debe ser correctamente comunicada en el artículo publicado, siguiendo las recomendaciones internacionales sintetizadas en la pauta de reporte STROBE (Strengthening the Reporting of Observational studies in Epidemiology) para estudios observacionales (http://www.strobe-statement.org/)[39].
Los estudios de casos y controles presentan diversas utilidades y fortalezas, demostrando en la historia haber sido la piedra angular del estudio de grandes problemáticas de salud pública. Sin embargo, su principal debilidad tiene que ver con que la exposición ocurrió en el pasado, lo que aumenta la ocurrencia de sesgos. Se ha propuesto controlar el efecto del sesgo de confusión mediante el análisis estratificado por técnicas de Mantel-Haenszel, pero como han estimado algunos autores, éste ha sido reemplazado en gran medida por los modelos multivariados de regresión estadística[40]. Lo mismo ha sucedido con el matching, cuya aplicación se ha visto un tanto disminuida a favor del uso de técnicas de regresión estadística[15],[16]. No obstante, siempre será una mejor opción el controlar los sesgos a nivel del diseño que del análisis estadístico. Así, el análisis estadístico más avanzado no salvará a un estudio mal diseñado: los controles deben seleccionarse con máxima rigurosidad.
Figura 1. Esquema de síntesis sobre los estudios de casos y controles. Fuente: diseñada por los propios autores.
Roles y contribuciones de los autores
MA, JS y CP son académicos de la Cátedra de Metodología de la Investigación Científica, en la que se circunscribe el desarrollo de la presente serie metodológica como una actividad investigativa de los ayudantes alumnos del curso.
Todos los autores contribuyeron en la planificación y escritura del manuscrito original.
DM, CP y MA: contribuyeron con el desarrollo de la Introducción, conceptos preliminares, medidas de asociación y tipos de estudios de casos y controles.
DM, MA y JS: ayudaron en el desarrollo de los sesgos en estudios de casos y controles. También aportaron los Ejemplos 1, 3 y 4.
DM, MA y CP: aportaron los Ejemplos 2 y 5.
DM y MA: realizaron la Figura 1.
Financiamiento
Los autores declaran que no hubo fuentes externas de financiamiento.
Conflictos de interés
Los autores completaron la declaración de conflictos de interés de ICMJE y declararon que no recibieron fondos por la realización de este artículo; no tienen relaciones financieras con organizaciones que puedan tener interés en el artículo publicado en los últimos tres años y no tienen otras relaciones o actividades que puedan influenciar en la publicación del artículo. Los formularios se pueden solicitar contactando al autor responsable o al Comité Editorial de la Revista.
Aspectos éticos
Este estudio no requirió la evaluación por parte de un comité de ética-científica, debido a que es un artículo de revisión.
 Esta obra de Medwave está bajo una licencia Creative Commons Atribución-NoComercial 3.0 Unported. Esta licencia permite el uso, distribución y reproducción del artículo en cualquier medio, siempre y cuando se otorgue el crédito correspondiente al autor del artículo y al medio en que se publica, en este caso, Medwave.
Esta obra de Medwave está bajo una licencia Creative Commons Atribución-NoComercial 3.0 Unported. Esta licencia permite el uso, distribución y reproducción del artículo en cualquier medio, siempre y cuando se otorgue el crédito correspondiente al autor del artículo y al medio en que se publica, en este caso, Medwave.
Case-control studies have been essential to the field of epidemiology and in public health research. In this design, data analysis is carried out from the outcome to the exposure, that is, retrospectively, as the association between exposure and outcome is studied between people who present a condition (cases) and those who do not (controls). They are thus very useful for studying infrequent conditions, or for those that involve a long latency period. There are different case selection methodologies, but the central aspect is the selection of controls. Data collection can be retrospective (obtained from clinical records) or prospective (applying data collection instruments to participants). Depending on the objective of the study, different types of case-control studies are available; however, all present a particular vulnerability to information bias and confounding, which can be controlled at the level of design and in the statistical analysis. This review addresses general theoretical concepts concerning case-control studies, including their historical development, methods for selecting participants, types of case-control studies, association measures, potential biases, as well as their advantages and disadvantages. Finally, concepts about the relevance on this study design are discussed, with a view to aid comprehension for undergraduate and graduate students of the health sciences. This is the third of a methodological series of articles on general concepts in biostatistics and clinical epidemiology developed by the Chair of Scientific Research Methodology at the School of Medicine, University of Valparaíso, Chile.
Author:
Diego Martínez[1], Cristian Papuzinski[1,2], Jana Stojanova[1,2], Marcelo Arancibia[1,2]
Citación: Martínez D, Papuzinski C, Stojanova J, Arancibia M. General concepts in biostatistics and clinical epidemiology: observational studies with case-control design. Medwave 2019;19(10):e7716 doi: 10.5867/medwave.2019.10.7716
Fecha de envío: 10/9/2019
Fecha de aceptación: 25/10/2019
Fecha de publicación: 7/11/2019
Origen: Este artículo es parte de una colección de “Notas metodológicas” acordada entre Medwave y la Cátedra de Metodología de la Investigación Científica de la Escuela de Medicina de la Universidad de Valparaíso.
Tipo de revisión: Con revisión por pares externa con tres revisores, a doble ciego.
Nos complace que usted tenga interés en comentar uno de nuestros artículos. Su comentario será publicado inmediatamente. No obstante, Medwave se reserva el derecho a eliminarlo posteriormente si la dirección editorial considera que su comentario es: ofensivo en algún sentido, irrelevante, trivial, contiene errores de lenguaje, contiene arengas políticas, obedece a fines comerciales, contiene datos de alguna persona en particular, o sugiere cambios en el manejo de pacientes que no hayan sido publicados previamente en alguna revista con revisión por pares.
Nombre/name: Rosa Eugenia Jiménez
Fecha/date: 2019-12-01 13:39:52
Comentario/comment:
No me parece comprensible la explicaciĂłn que dan sobre el odds ratio en este artĂculo metodolĂłgico. Entiendo las dificultades de explicar el significado de este indicador de la fuerza de la asociaciĂłn entre dos variables cualitativas dicotĂłmicas que se utiliza preferentemente en los estudios de casos y controles. Pero estas dificultades no justifican explicaciones sin sentido. Cambiar la palabra probabilidad (o riesgo) por posibilidad no mejora las cosas, aunque Tapia y Nieto (Tapia JA, Nieto FJ. RazĂłn de posibilidades: una propuesta de traducciĂłn de la expresiĂłn odds ratio. Salud Publica Mex 1993;35:119-121) crean y justifiquen que la mejor traducciĂłn para odds ratio es precisamente “razĂłn de posibilidades”. El problema aquĂ no es semántico sino conceptual.
La dificultad de explicar la naturaleza y el significado del odds ratio o razĂłn de odds subyace en el hecho de que la palabra odds del inglĂ©s es de difĂcil traducciĂłn al español. Por eso, la explicaciĂłn del odds ratio debe comenzar por la explicaciĂłn de lo que la palabra odds significa en este caso.
Decir que “Esta medida representa el cociente entre la chance (Odds ratio) de exposición en el grupo de casos y en el grupo de controles, interpretada como cuántas veces más posibilidades tienen los casos de haber estado expuestos al factor estudiado en comparación con los controles” no es, a mi juicio, correcto. La chance o el chance, según la Real Academia de la Lengua Española (RAE) significa “oportunidad”, algo que tampoco resulta claro para alguien que desea conocer lo que es o representa el odds ratio y “cuántas veces más posibilidades” resulta confuso. Por otro lado, el odds ratio también es la razón casos/controles en el grupo de expuestos dividida entre la razón casos/controles en el grupo de no expuestos, aunque se trate de un estudio de casos y controles.
Mi opiniĂłn es que, si se pretende que alguien no experto en estadĂstica o en metodologĂa o en epidemiologĂa entienda quĂ© es el odds ratio (o razĂłn de odds) se debe comenzar explicando bien lo que significa el odds.
Para comentar debe iniciar sesión
Medwave publica las vistas HTML y descargas PDF por artículo, junto con otras métricas de redes sociales.
Paneth N, Susser E, Susser M. Origins and early development of the case-control study: Part 1, Early evolution. Soz Praventivmed. 2002;47(5):282-8. | CrossRef | PubMed |Shiode N, Shiode S, Rod-Thatcher E, Rana S, Vinten-Johansen P. The mortality rates and the space-time patterns of John Snow's cholera epidemic map. Int J Health Geogr. 2015 Jun 17;14:21. | CrossRef | PubMed |Paneth N. Assessing the contributions of John Snow to epidemiology: 150 years after removal of the broad street pump handle. Epidemiology. 2004 Sep;15(5):514-6. | CrossRef | PubMed |Lane-Claypon J. A further report on cancer of the breast. In: Reports on public health and medical subjects. London: Ministry of Health; 1926. | Link |Müller F. Tabakmissbrauch und Lungencarzinom. Ztschr Krebforsch. 1939;49:57-85. Paneth N, Susser E, Susser M. Origins and early development of the case-control study: Part 2, The case-control study from Lane-Claypon to 1950. Soz Praventivmed. 2002;47(6):359-65. | PubMed |Doll R, Hill AB. Smoking and carcinoma of the lung; preliminary report. Br Med J. 1950 Sep 30;2(4682):739-48. | CrossRef | PubMed |Moss AR, Osmond D, Bacchetti P, Chermann JC, Barre-Sinoussi F, Carlson J. Risk factors for AIDS and HIV seropositivity in homosexual men. Am J Epidemiol. 1987 Jun;125(6):1035-47. | PubMed |Papuzinski C, Martínez F. Case-control studies – the retrospective perspective. Medwave. 2014 Mar 27;14(2):e5925. | CrossRef | PubMed |Sackett D, Haynes R, Guyatt G, Tugwell P. Clinical epidemiology: a basic science for clinical medicine. 2nd ed. Boston: Little Brown and Company; 1991. | Link |Schulz KF, Grimes DA. Case-control studies: research in reverse. Lancet. 2002 Feb 2;359(9304):431-4. | PubMed |Lazcano-Ponce E, Salazar-Martínez E, Hernández-Ávila M. Estudios epidemiológicos de casos y controles. Fundamento teórico, variantes y aplicaciones. Salud Pública Mex. 2001;43(2):135-50. | Link |Gómez-Restrepo C. Estudios de casos y controles. In: Ruiz Á, Gómez-Restrepo C, editors. Epidemiología clínica: investigación clínica aplicada. 2nd ed. Bogotá: Editorial Médica Panamericana; 2015. Grimes DA, Schulz KF. Compared to what? Finding controls for case-control studies. Lancet. 2005 Apr 16-22;365(9468):1429-33. | PubMed |Langholz B, Richardson D. Are nested case-control studies biased? Epidemiology. 2009 May;20(3):321-9. | CrossRef | PubMed |Kumar A, Dogra S, Kaur A, Modi M, Thakur A, Saluja S. Approach to sample size calculation in medical research. Curr Med Res Pract. 2014 Mar 1;4(2):87-92. | CrossRef |Wacholder S, McLaughlin JK, Silverman DT, Mandel JS. Selection of controls in case-control studies. I. Principles. Am J Epidemiol. 1992 May 1;135(9):1019-28. | PubMed |Viera AJ. Odds ratios and risk ratios: what's the difference and why does it matter? South Med J. 2008 Jul;101(7):730-4. | CrossRef | PubMed |Maclure M. The case-crossover design: a method for studying transient effects on the risk of acute events. Am J Epidemiol. 1991 Jan 15;133(2):144-53. | PubMed |Molina-Arias M. Estudios de casos cruzados. Rev Pediatr Aten Primaria. 2015 Dec;17(68):373-6. | Link |Lombardi DA. The case-crossover study: a novel design in evaluating transient fatigue as a risk factor for road traffic accidents. Sleep. 2010 Mar;33(3):283-4. | PubMed |Manterola C, Otzen T. Los Sesgos en Investigación Clínica. Int J Morphol [Internet]. 2015 Sep;33(3):1156-64. | Link |Grimes DA, Schulz KF. Bias and causal associations in observational research. Lancet. 2002 Jan 19;359(9302):248-52. | PubMed |García Marcos L, Guillén Pérez J, Orejas Rodríguez-Arango G. Epidemiología y metodología aplicada a la pediatría (V): Sesgos. An Esp Pediatr. 1999;50:519-524. | Link |Barraza F, Arancibia M, Madrid E, Papuzinski C. General concepts in biostatistics and clinical epidemiology: Random error and systematic error. Medwave. 2019 Aug 27;19(7):e7687. | CrossRef | PubMed |Cataldo R, Arancibia M, Stojanova J, Papuzinski C. General concepts in biostatistics and clinical epidemiology: Observational studies with cross-sectional and ecological designs. Medwave. 2019 Sep 25;19(8):e7698. | CrossRef | PubMed |Rose S, Laan MJ van der. Why match? Investigating matched case-control study designs with causal effect estimation. Int J Biostat. 2009 Jan 6;5(1):Article 1. | CrossRef |Mansournia MA, Jewell NP, Greenland S. Case–control matching: effects, misconceptions, and recommendations. Eur J Epidemiol. 2018 Jan 3;33(1):5-14. | CrossRef |Hidalgo B, Goodman M. Multivariate or multivariable regression? Am J Public Health [Internet]. 2013 Jan [cited 2019 Jul 22];103(1):39–40. | CrossRef | PubMed |Lu CY. Observational studies: a review of study designs, challenges and strategies to reduce confounding. Int J Clin Pract. 2009 May;63(5):691-7. | CrossRef |Rosenbaum PR, Rubin DB. Reducing Bias in Observational Studies Using Subclassification on the Propensity Score. J Am Stat Assoc . 1984 Sep;79(387):516–24. | CrossRef |Ghaemi S. Why you cannot believe your eyes: the three C’s. In: A clinician’s guide to statistics and epidemiology in mental health: measuring truth and uncertainty. Cambridge: Cambridge University Press; 2009. Perillo MG. Choice of controls in case-control studies. J Manipulative Physiol Ther. 1993 Nov-Dec;16(9):578-85. | PubMed |






 Estudios originales
Estudios originales